LightGBM Training with Dask
Overview
LightGBM is a popular algorithm for supervised learning with tabular data. It has been used in many winning solutions in data science competitions.
The lightgbm Python package allows for efficient single-machine training using multithreading. However, the amount of training data you can use is limited by the size of that one machine. To solve this problem, LightGBM supports distributed training using several different interfaces. This tutorial explores distributed LightGBM training using Dask.
In this tutorial, you’ll learn:
- how distributed training works for LightGBM, and what types of performance changes you can expect when you add more data or machines
- how to use Dask to accelerate LightGBM model training
- how to diagnose performance problems and speed up training
This tutorial does NOT cover how to improve the statistical performance of LightGBM models. There is already excellent coverage of that topic on the internet.
Part 1: How Distributed Training for LightGBM Works
How LightGBM Training Can Be Parallelized
This tutorial assumes that you have some familiarity with Gradient Boosted Decision Trees (GBDTs) generally and LightGBM specifically. If you do not, please refer to “Introduction to Boosted Trees” in the XGBoost documentation, then return to this tutorial.
In LightGBM, like in other gradient-boosted decision tree algorithms, trees are built one node at a time. When building a tree, a set of possible “split points” (tuples of (feature, threshold)) is generated, and then each split point is evaluated. The one that leads to the best reduction in loss is chosen and added to the tree. Nodes are added to the tree this way until tree-specific stopping conditions are met. Trees are added to the model this way until model-wide stopping conditions are met. To make a prediction with the model, you pass new data through all of the trees and add the output of the trees together.
Because trees need to be built sequentially like this, GBDTs can’t benefit from building trees in parallel the way that random forests can. However, they can still be sped up by adding more memory and CPU. This is because the work that needs to be done to choose a new tree node is parallelizable.
Consider this very-oversimplified pseudocode for how one new node is added to a tree in LightGBM.
for split_point in split_points:
loss = 0
new_model = global_model.copy()
new_model.current_tree.add(split_point)
for observation in data:
predicted_value = new_model.predict(observation)
loss += loss_function(predicted_value, observation.actual_value)
When you see a for loop or something being summed, there’s opportunity to parallelize! That is exactly where LightGBM is able to apply parallelism to speed up training. The main training process can assign subsets of the data to multiple threads, and tell each of them “evaluate all the split points against your data and tell me how it goes”. Adding more CPUs or GPUs allows you to efficiently use more threads, which means more subsets can be evaluated at the same time, which reduces the total time it takes for each of these “add a node to the tree” steps.
To get access to more CPUs or GPUs, you have these options:
- get a bigger machine
- get more machines
When LightGBM and other machine learning libraries talk about “distributed training”, they’re talking about the choice “get more machines”.
How LightGBM Distributed Training Works
In the single-machine case, parallelization is really efficient because those threads created by the main program don’t need to move any data around. They all have shared access to the dataset in memory, and each access different pieces of it.
In a distributed setting, with multiple machines, this is more complicated. Subsets of the training data need to be physically located on the machines that are contributing to training. These machines are called “workers”.
LightGBM comes bundled with its own distributed training setup, called LightGBM::Network. This interface uses sockets by default, but can be set up to use MPI for communication.
LightGBM’s distributed training comes in two flavors: “data parallel” and “feature parallel”. For full details, see “Optimization in Parallel Learning” (LightGBM docs).
In Feature Parallel distributed learning, a full copy of the training data is replicated to each worker. Each time a node needs to be added to the current tree, each worker searches split points over a subset of the features. Each worker is responsible for communicating around information about the best splits for the features that worker is responsible for. Feature Parallel mode is appropriate for cases where the training data comfortably fits in memory on each worker, and with relatively “wide” datasets (many features).
In Data Parallel distributed learning, the training data are partitioned horizontally. In other words, each worker contains a subset of rows but all columns from the training data. Each time a node needs to be added to the current tree, each worker builds a local feature histogram for all features, based on the chunk of the training data on that instance. The cluster then performs a “Reduce Scatter” (see image below), where each worker is responsible for merging feature histograms for a subset of features, and then syncing the global best splits back to other workers. Data Parallel mode is appropriate where the training data is very large.
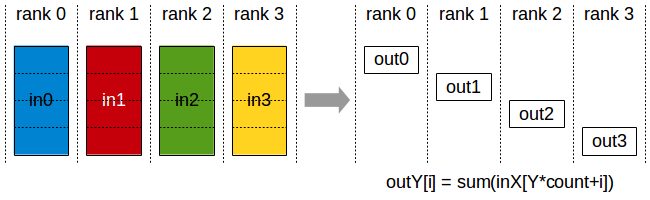
image credit: NCCL docs
The training process can only add one tree node at a time. If the number and size of workers that you have is fixed, then reduction in training times come from reducing the time to add one node and reducing the total number of nodes added.
The total number of tree nodes that will be created across all trees depends on:
- number of nodes per tree:
max_depth,min_gain_to_split,min_data_in_leaf,min_sum_hessian_in_leaf,num_leaves - number of trees:
num_iterations,early_stopping_round
The amount of time it takes to create each tree node depends on:
- number of rows
- number of features in the training data
- number of splits to explore
Part 2: LightGBM Training with Dask
In Part 1, you learned some of the intuition behind distributed LightGBM training. In this section, you’ll get hands-on exposure to distributed LightGBM training with Dask.
If you want to just get the code and paste it into a notebook yourself, expand the cell below.
training example
import dask.array as da
import lightgbm as lgb
from dask.distributed import Client, wait
from dask_ml.metrics import mean_absolute_error
from dask_saturn import SaturnCluster
n_workers = 3
cluster = SaturnCluster(
n_workers=n_workers,
scheduler_size='medium',
worker_size='4xlarge',
nprocs=1
)
client = Client(cluster)
client.wait_for_workers(n_workers)
cluster
num_rows = 1e6
num_features = 100
num_partitions = 10
rows_per_chunk = num_rows / num_partitions
data = da.random.random(
size=(num_rows, num_features),
chunks=(rows_per_chunk, num_features)
)
labels = da.random.random(
size=(num_rows, 1),
chunks=(rows_per_chunk, 1)
)
data = data.persist()
labels = labels.persist()
_ = wait(data)
_ = wait(labels)
n_rounds = 50
dask_reg = lgb.DaskLGBMRegressor(
client=client,
silent=False,
max_depth=5,
random_state=708,
objective="regression_l2",
learning_rate=0.1,
tree_learner="data",
n_estimators=n_rounds,
min_child_samples=1,
n_jobs=-1
)
dask_reg.fit(
X=data,
y=labels
)
holdout_data = da.random.random(
size=(1000, num_features),
chunks=(50, num_features)
)
holdout_labels = da.random.random(
size=(num_rows, 1),
chunks=(rows_per_chunk, 1)
)
preds = dask_reg.predict(
X=holdout_data
)
mae = mean_absolute_error(
y_true=holdout_labels,
y_pred=preds,
compute=true
)
print(f"Mean Absolute Error: {mae}")
Set Up Environment
In Saturn Cloud, go to the resources page and create a new Jupyter server. Choose the following settings:
- name:
lightgbm-tutorial - image: saturncloud/saturn:2020.10.23
- disk space: 10 Gi
- size: Medium - 2 cores - 4 GB RAM
- start script:
pip install 'lightgbm>=3.2.0'
Next, set up your Dask cluster within the Saturn Cloud resource page. Use the following settings:
- number of workers: 3
- scheduler size: Medium
- worker size: 4xLarge
- number of worker processes: 1
- number of worker threads: optimal (default)
Start up the Jupyter server, and go into JupyterLab.
Import the libraries used in this example.
import dask.array as da
import lightgbm as lgb
from dask.distributed import Client, wait
from dask_ml.metrics import mean_absolute_error
from dask_saturn import SaturnCluster
cluster = SaturnCluster()
client = Client(cluster)
client.wait_for_workers(3)
cluster
Load Data
lightgbm.dask allows you to train on Dask collections, like Dask DataFrames and Dask Arrays. This is really powerful because it means that you never have to have a single machine that’s big enough for all of your training data.
These collections are lazy, which means that even though they look and feel like a single matrix, they’re actually more like a list of function calls that each return a chunk of a matrix. With these collections, you don’t need to (and shouldn’t!) create the entire dataset on one machine and then distribute it to all of the workers. Instead, Dask will tell each of the workers “hey, read these couple chunks into your memory”, and each worker does that on their own and keeps track of their own piece of the total dataset.
There is a lot more information on this in the Dask documentation.
For this tutorial, create some random numeric data using dask.array.
import dask.array as da
import lightgbm as lgb
num_rows = 1e6
num_features = 100
num_partitions = 10
rows_per_chunk = num_rows / num_partitions
data = da.random.random(
size=(num_rows, num_features),
chunks=(rows_per_chunk, num_features)
)
labels = da.random.random(
size=(num_rows, 1),
chunks=(rows_per_chunk, 1)
)
At this point, data and labels are lazy collections. They won’t be read into the workers' memory until some other computation asks for them. If we start training a model right now, the training will block until those arrays have been materialized. Dask’s garbage collection might also remove them from memory when training ends, which means they’ll have to be recreated if we want to train another model.
To avoid this situation and to make iterating on the model faster, use persist(). This says “hey Dask, go materialize all the pieces of this matrix and then keep them in memory until I ask you to delete them”.
data = data.persist()
labels = labels.persist()
_ = wait(data)
_ = wait(labels)
Train
Now that the data have been set up, it’s time to train a model!
n_rounds = 50
dask_reg = lgb.DaskLGBMRegressor(
client=client,
silent=False,
max_depth=5,
random_state=708,
objective="regression_l2",
learning_rate=0.1,
tree_learner="data",
n_estimators=n_rounds,
min_child_samples=1,
n_jobs=-1
)
dask_reg.fit(
X=data,
y=labels
)
The DaskLGBMRegressor class from lightgbm accepts any parameters that can be passed to lightgbm.LGBRegressor, with one exception: num_thread. Any value for num_thread that you pass will be ignored, since the Dask estimators reset num_thread to the number of logical cores on each Dask worker.
For details on the supported parameters in lightgbm, see the LightGBM parameter docs.
Evaluate
Training with lightgbm.dask produces a model object with a regular lightgbm.basic.Booster, the exact same model object produced by single-machine training.
type(dask_reg.booster_)
# lightgbm.basic.Booster
lightgbm.dask model objects also come with a predict() method that can be used to create predictions on a Dask Array or Dask DataFrame.
Run the code below to create a validation set and test how well the model we trained in previous steps performs.
holdout_data = da.random.random(
size=(1000, num_features),
chunks=(50, num_features)
)
holdout_labels = da.random.random(
size=(num_rows, 1),
chunks=(rows_per_chunk, 1)
)
preds = dask_reg.predict(
X=holdout_data
)
Given these predictions, you can use the built-in metrics from dask-ml to evaluate how well the model performed. These metrics functions are similar to those from scikit-learn, but take advantage of the fact that their inputs are Dask collections. For example, dask_ml.metrics.mean_absolute_error(), will split up responsibility for computing the MAE into many smaller tasks that work on subsets of the validation data. This runs faster than doing the predictions on the client, and allows you to perform evaluations on very large datasets without needing to move those datasets around or pull them back to the client.
from dask_ml.metrics import mean_absolute_error
mae = mean_absolute_error(
y_true=holdout_labels,
y_pred=preds,
compute=true
)
print(f"Mean Absolute Error: {mae}")
Deploy
The model object produced by lgb.DaskLGBMRegressor.fit() is an instance of lgb.DaskLGBMRegressor, but that doesn’t mean you have to use Dask at scoring time.
See “Saving Dask Models” in the LightGBM documentation for details on how to deploy models trained on Dask.
Part 3: Speeding Up Training
In the previous sections, you learned how to train and evaluate a LightGBM model using Dask. This sections describes how to speed up model training.
Change Dask Settings
Before getting into the specifics of LightGBM, you might be able to speed up training by taking one of the following actions that are generally useful in machine learning training on Dask.
- restart the workers
- increase the worker size
- add more workers
- use all available cores on each Dask worker
Make Your Model Smaller
In “How LightGBM Distributed Training Works”, you learned how different parameters of characteristics of the input data impact training time. This section describes how to adjust those parameters to improve training time.
Note that some of these changes might result in worse statistical performance.
Grow Shallower Trees
To grow shallower trees, you can change the following LightGBM parameters. Growing shallower trees might also act as a form of regularization that improves the statistical performance of your model.
See these suggestions in the LightGBM parameter tuning docs.
- decrease
max_depth - decrease
num_leaves - increase
min_gain_to_split - increase
min_data_in_leafandmin_sum_hessian_in_leaf
Grow Fewer Trees
LightGBM allows several methods to control the number of total trees in the model. Follow the suggestions in the LightGBM parameter tuning docs.
Early Stopping in lightgbm
As of this writing,lightgbm.dask does not support
early stopping, so Dask training cannot benefit from the speedups that early stopping offers.Consider Fewer Splits
In any tree-based supervised learning model, the process of growing each tree involves evaluating “split points”. A split point is a combination of a feature and a threshold on that feature’s values.
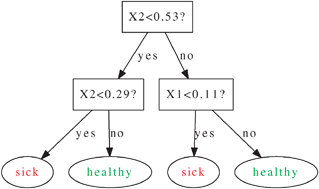
image credit: Geurts et al (2009), Royal Society of Chemistry
You can substantially reduce the training time by decreasing the number of these “split points” that must be considered to create a new node in the tree.
Follow these suggestions in the LightGBM parameter tuning docs related to reducing the number of split points used:
- enable feature pre-filtering
- decrease
max_binormax_bin_by_feature - increase
min_data_in_bin - decrease
feature_fraction - decrease
max_cat_threshold
Perform Feature Selection
To reduce the number of features, consider adding a preprocessing step that trains a model on a smaller dataset and performs feature selection.
Use Less Data
LightGBM allows the use of bagging, randomly selecting a subset of rows to use in training. For more details, see the LightGBM parameter tuning docs.
- decrease
bagging_fraction - increase
bagging_freq
Conclusion
In this tutorial, you learned how distributed training can speed up LightGBM workflows and / or allow you to train models using more input data. You also saw how to implement this using Python and Dask.
To learn more about these topics, see the links below.
Dask
- Managing Computation (docs.dask.org)
- “Managing Memory” (docs.dask.org)
- “Processes and Threads (docs.dask.org)"
GBDTs
- Decision Tree Leaf-Wise vs. Level-Wise Traversal (Stack Overflow)
- Introduction to Boosted Trees (XGBoost docs)
- Explanation of min_child_weight
LightGBM
- GPU Tuning Guide and Performance Comparison (LightGBM docs)
- Learning Control Parameters (LightGBM docs)
- Optimization in Parallel Learning (LightGBM docs)
- XGBoost and LightGBM on Large Datasets, Possible Solutions (towardsdatascience)
Other Concepts
Need help, or have more questions? Contact us at:
- support@saturncloud.io
- On Intercom, using the icon at the bottom right corner of the screen
We'll be happy to help you and answer your questions!
