Batch Inference with PyTorch
In this example, we will perform a large volume image classification task on a GPU cluster with a pre-built model. We’re using the Stanford Dogs Dataset, so we will provide an image of a dog, and ask Resnet50 to give us the correct breed label.
Dataset: Stanford Dogs
Model: Resnet50
from dask_saturn import SaturnCluster
from dask.distributed import Client
from torchvision import datasets, transforms, models
import re
import s3fs
import dask
import toolz
import torch
import matplotlib.pyplot as plt
#### Load label targets ####
s3 = s3fs.S3FileSystem(anon=True)
with s3.open('s3://saturn-public-data/dogs/imagenet1000_clsidx_to_labels.txt') as f:
classes = [line.strip() for line in f.readlines()]
Assigning Objects to GPU Resources
If you are going to run any processes on GPU resources in a cluster, you need all your objects to be explicitly told this. Otherwise, it won’t seek out GPU resources. However, if you use a functional setup (as we are going to do later) you’ll need to do this INSIDE your function. Our architecture below will have all that written in.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
Create and Connect Cluster
This will create and start a cluster if you haven’t already created one. If you need more information about working with clusters in Dask, we have reference material to help.
cluster = SaturnCluster(
n_workers = 6,
scheduler_size = 'medium',
worker_size = 'g4dn4xlarge',
nthreads = 16
)
client = Client(cluster)
client.wait_for_workers(3)
client.restart()
Notice that this will wait until at least three of the requested six clusters is ready to use.
Preprocessing Images
Our goal here is to create a nicely streamlined workflow, including loading, transforming, batching, and labeling images, which we can then run in parallel. Our data preprocessing function is set up to take images from S3, load and transform them, and extract the label and the unique identifier from the filepath.
@dask.delayed
def preprocess(path, fs=__builtins__):
'''
Ingest images directly from S3, apply transformations,
and extract the ground truth and image identifier. Accepts
a filepath.
'''
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(250),
transforms.ToTensor(),
])
with fs.open(path, 'rb') as f:
img = Image.open(f).convert("RGB")
nvis = transform(img)
truth = re.search('dogs/Images/n[0-9]+-([^/]+)/n[0-9]+_[0-9]+.jpg', path).group(1)
name = re.search('dogs/Images/n[0-9]+-[a-zA-Z-_]+/(n[0-9]+_[0-9]+).jpg', path).group(1)
return [name, nvis, truth]
This function does a number of things for us.
- Open an image file from S3
- Apply transformations to image
- Retrieve a unique identifier for the image
- Retrieve the ground truth label for the image
But you’ll notice that this has a @dask.delayed decorator, so we can queue it without it running immediately when called. Because of this, we can use some list comprehension strategies to create our batches and get them ready for our inference.
If you’re new to the idea of delayed functions, you might want to visit our deep dive article about Dask concepts.
This function restructures our data to make it work better with PyTorch’s expectations.
@dask.delayed
def reformat(batch):
'''
Structure the dataset to allow inference in batches.
'''
flat_list = [item for item in batch]
tensors = [x[1] for x in flat_list]
names = [x[0] for x in flat_list]
labels = [x[2] for x in flat_list]
tensors = torch.stack(tensors).to(device)
return [names, tensors, labels]
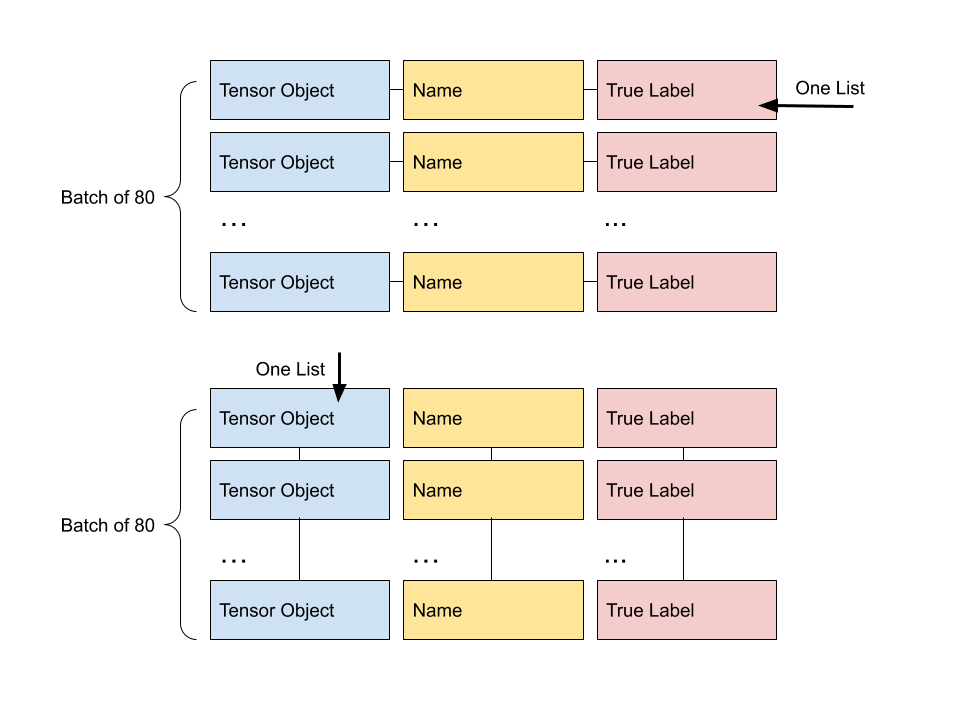
This diagram explains what the process is doing- we go from three item wide lists initially, to long lists of a single data type (tensors, names, or labels).
Evaluation Functions
This takes our results from the model, and a few other elements, to return nice readable predictions and the probabilities the model assigned. From here, we’re nearly done! We want to pass our results back to S3 in a tidy, human readable way, so the rest of the function handles that. It will iterate over each image because these functionalities are not batch handling. is_match is one of our custom functions, which you can check out below.
def evaluate_pred_batch(batch, gtruth, classes):
'''
Accepts batch of images, returns human readable predictions.
'''
_, indices = torch.sort(batch, descending=True)
percentage = torch.nn.functional.softmax(batch, dim=1)[0] * 100
preds = []
labslist = []
for i in range(len(batch)):
pred = [(classes[idx], percentage[idx].item()) for idx in indices[i][:1]]
preds.append(pred)
labs = gtruth[i]
labslist.append(labs)
return(preds, labslist)
def is_match(label, pred):
'''
Evaluates human readable prediction against ground truth.
'''
if re.search(label.replace('_', ' '), str(pred).replace('_', ' ')):
match = True
else:
match = False
return(match)
Inference Workflow Function
Now, we aren’t going to patch together all these computations by hand, instead we have assembled them in one single delayed function that will do the work for us. Importantly, we can then map this across all our batches of images across the cluster!
PyTorch has the companion library torchvision which gives us access to a number of handy tools, including copies of popular models like Resnet. You can learn more about the available models in the torchvision documentation.
@dask.delayed
def run_batch_to_s3(iteritem):
'''
Accepts iterable result of preprocessing, generates inferences and evaluates.
'''
names, images, truelabels = iteritem
with s3.open('s3://saturn-public-data/dogs/imagenet1000_clsidx_to_labels.txt') as f:
classes = [line.strip() for line in f.readlines()]
# Retrieve, set up model
resnet = models.resnet50(pretrained=True)
resnet = resnet.to(device)
with torch.no_grad():
resnet.eval()
pred_batch = resnet(images)
#Evaluate batch
preds, labslist = evaluate_pred_batch(pred_batch, truelabels, classes)
#Organize prediction results
outcomes = []
for j in range(0, len(images)):
match = is_match(labslist[j], preds[j])
outcome = {'name': names[j], 'ground_truth': labslist[j],
'prediction': preds[j], 'evaluation': match}
outcomes.append(outcome)
return(outcomes)
Run Inference Workflow
Notice that we’re going to use client methods below to ensure that our tasks are distributed across the cluster, run, and then retrieved.
Preprocess image data (lazy evaluation)
s3fpath = 's3://saturn-public-data/dogs/Images/*/*.jpg'
batch_breaks = [list(batch) for batch in toolz.partition_all(80, s3.glob(s3fpath))]
image_batches = [[preprocess(x, fs=s3) for x in y] for y in batch_breaks]
image_batches = [reformat(result) for result in image_batches]
Run inference workflow on batches
futures = client.map(run_batch_to_s3, image_batches)
futures_gathered = client.gather(futures)
futures_computed = client.compute(futures_gathered, sync=False)
results = []
errors = []
## Error handling allows us to capture when an input image is broken
for fut in futures_computed:
try:
result = fut.result()
except Exception as e:
errors.append(e)
logging.error(e)
else:
results.extend(result)
Evaluate Output
In this section, we’ll review the results our inference job produced. This calculates which predictions were true or false, and calculates the percent accurate.
true_preds = [x['evaluation'] for x in results if x['evaluation'] == True]
false_preds = [x['evaluation'] for x in results if x['evaluation'] == False]
len(true_preds)/len(results)*100
Lessons Learned
- You can apply
@dask.delayedto your custom code to allow parallelization with nearly zero refactoring - Objects that are needed for a parallel task on GPU need to be assigned to a GPU resource
- Passing tasks to the workers uses mapping across the cluster for peak efficiency And, of course, having multiple workers makes the job a lot faster!
Need help, or have more questions? Contact us at:
- support@saturncloud.io
- On Intercom, using the icon at the bottom right corner of the screen
We'll be happy to help you and answer your questions!
