Resources Won't Start - Jupyter, Dask, or Deployments
Follow this guide for tips on what to do when any of your resources (i.e. Jupyter server, Dask cluster workers, or Deployments) won’t start up.
There are several steps involved in starting a resource, as can be seen on the Resource page. Understanding each step helps for troubleshooting or speeding up launch time.
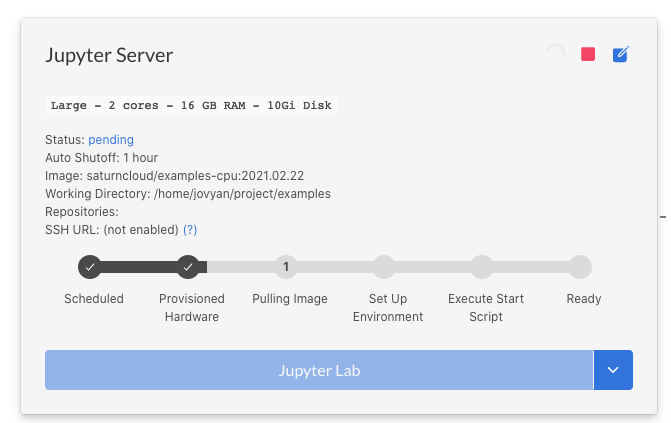
Hardware provisioning
Hardware provisiong involves requesting instances from AWS. With Saturn Cloud Hosted there should not be any problems with this step. For enterprise installations, scroll down to the Enterprise-specific troubleshooting section.
Large images
The “Pulling Image” step depends on how large the image is. The number of packages and artifacts in the image contributes to the disk size of the image, and larger images will take longer to load. If this step is taking too long, try using another image with fewer packages or artifacts.
Start script fails
If you have a Start Script set up for your resource, this gets executed each time a resource starts. If this fails, you will see an “error” status for the resource. Click the “error” link to view the logs to see what went wrong.
Enterprise-specific troubleshooting
There are AWS-related issues that can come in an enterprise installation.
AWS vCPU Limits
AWS accounts start off with pretty strict vCPU limits, so if you are starting with a fresh account, or are launching more machines than you used to, you might be hitting these limits. AWS has a quota in place which limits the number of concurrent vCPUs you can use, which are organized by tier. You can confirm that you are having this issue by running:
aws autoscaling describe-scaling-activities
You should see a message like this:
{
"ActivityId": "2323-234234-234234",
"AutoScalingGroupName": "saturn-cluster-demo-16xlarge20202323242342342",
"Description": "Launching a new EC2 instance. Status Reason: You have
requested more vCPU capacity than your current vCPU limit of 32 allows
for the instance bucket that the specified instance type belongs to.
Please visit http://aws.amazon.com/contact-us/ec2-request to request an
adjustment to this limit. Launching EC2 instance failed.",
"Cause": "At 2020-07-14T13:13:24Z an instance was started in response
to a difference between desired and actual capacity, increasing the
capacity from 0 to 1.",
"StartTime": "2020-07-14T13:13:25.764Z",
"EndTime": "2020-07-14T13:13:25Z",
"StatusCode": "Failed",
"StatusMessage": "You have requested more vCPU capacity than your
current vCPU limit of 32 allows for the instance bucket that the
specified instance type belongs to. Please visit
http://aws.amazon.com/contact-us/ec2-request to request an adjustment
to this limit. Launching EC2 instance failed.",
"Progress": 100,
"Details": "{\"Subnet ID\":\"subnet-24234234234234234\",
\"Availability Zone\":\"eu-west-3a\"}"
},
To resolve this, navigate to the AWS Service Quotas Console. From there select EC2.
- For CPU instances, increase the value for Running On-Demand Standard (A, C, D, H, I, M, R, T, Z) instances.
- For T4 GPUs, it’s Running On-Demand G instances
- For V100 GPUs it’s Running On-Demand P instances.
AWS generally takes 24 hours to respond to limit increases.
Availability zone doesn’t support specific instance types
In rare cases, the availability zone your Saturn Cloud is installed on may not support some of the instances types we use. Our enterprise installer checks for this so most installations will not have this problem. If you are running into this issue, please contact us at support@saturncloud.io.
Need help, or have more questions? Contact us at:
- support@saturncloud.io
- On Intercom, using the icon at the bottom right corner of the screen
We'll be happy to help you and answer your questions!
